概述
大数据需要多台服务器集群, 如果用云服务器的话让很多新手都望之却步, 我们来配置穷逼本地虚拟机集群.这也为后面的hadoop和spark开发做准备.让我们键盘作伴开始吧.
安装Ubuntu Server
在安装ubuntu之前,需要安装虚拟机软件,本文使用Vmare15, 安装配置自行搞定.
下面说明介个问题:
- VMare 网络适配器连接方式:
- 桥接模式:这个模式就像是虚拟出来的一个独立的主机,可以访问物理网络,但是需要自行配置IP地址, 子网掩码,而且必须和宿主机器处于同一网段.
- NAT模式: 这种是应用在Internet网关和路由器上,虚拟出一个网卡,虚拟出来的网卡和虚拟机的IP处于一个地址段.
- 仅主机模式(host only): 只是让主机和虚拟机之间的网络互动, 虚拟机访问不到Internet.
虚拟机安装完毕!!!!
设置网络模式:
- vmare: 编辑 -> 选择网络选择器 -> 将vmnet1主机模式设置 ->
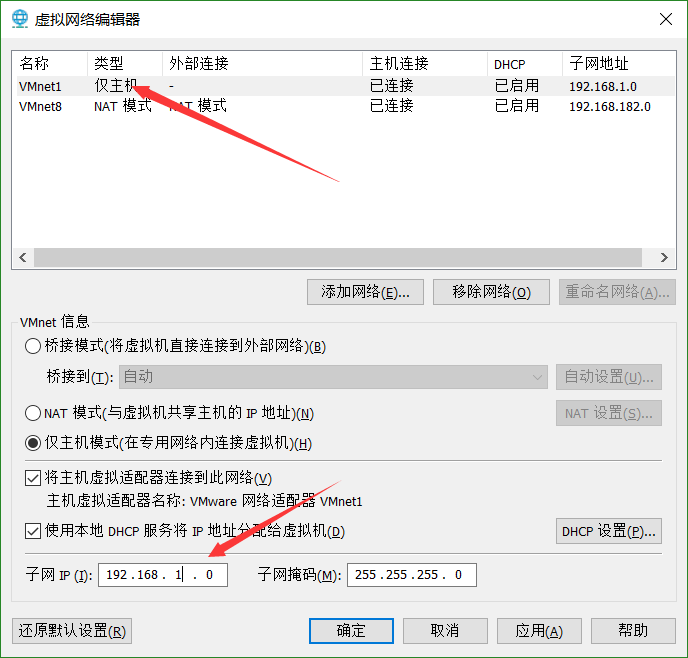
- 设置主机的网络: 打开网络和Internet设置 -> 以太网 -> 更换适配器选项 -> 右键VMnet1属性 ->
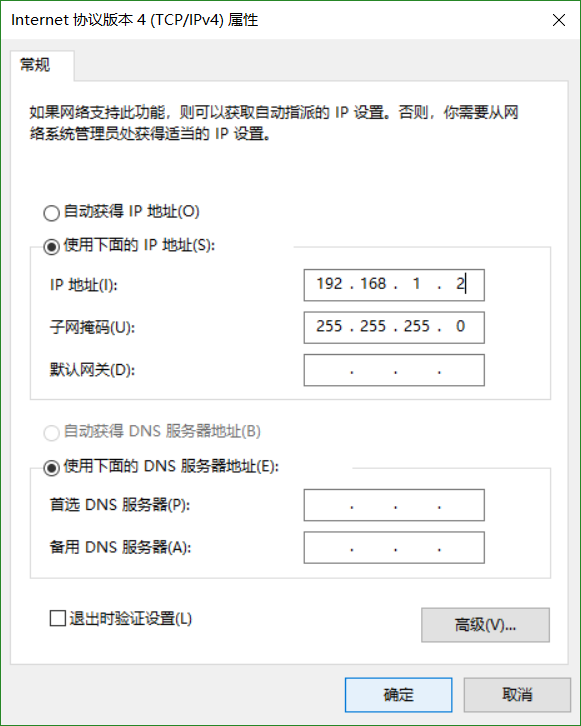
设置基本原则: 虚拟机采用静态IP,与VMare1处于一个网段内.
虚拟机选择桥接模式
修改系统参数
- 修改主机名: /etc/hostname
- 修改系统网络参数: /etc/network/interfaces
1
2
3
4
5
6
7auto eth0
iface eth0 inet dhcp dhcp的配置
iface eth0 inet static # eth0设置为静态IP
address 192.168.1.45
netmast 255.255.255.0
gateway 192.168.1.1
broadcast 192.168.1.255mac地址配置文件: /etc/udev.rules.d/70-persistent-net.rules 如果克隆虚拟机找不到网卡就rm掉这个文件.
1
2
3
4网络生效
sudo /etc/init.d/networking restart
or
sudo ifup eth0- 修改DNS配置
配置: 在/etc/resolvconf/resolv.conf.d/新建一个tail文件写入:
1
2nameserver 192.168.1.1
nameserver xx.xx.xx.xx
远程控制server
1 | sudo apt update |
安装JDK
使用没有界面的jdk所用需要使用wget来下载jdk,安装openjdk也是一样;
1 | 只有这样才能下载成功 |
测试Scala
1 | xyxj@u18_data1:~$ scala |
环境变量
1 | jdk |
免密钥登录
需要使用ssh-keygen创建一对公私钥. 由于ubuntu18已经安装ssh,如果没有安装需要安装:
1 | sudo apt install ssh |
略…..
- 先将win10免密钥登录主虚拟机
将win10上的公钥拷贝到/.ssh/authorized_keys
- 然后将各个界面的公钥相互验证….完毕
安装Hadoop
官网: 全部版本下载地址
下载2.6.0版本
1 | $ wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz |
如果下载的很慢就使用ftp:
注意ftp连接失败的话, 看看端口号是否21改成22,即使用sftp连接.
环境变量
1 | export HADOOP_HOME=/usr/local/hadoop |
必须配置JAVA_HOME
- core-site.xml
1 | <configuration> |
- yarn-site.xml
1 | <configuration> |
- hdfs-site.xml , 创建namenode和datanode
1 | sudo mkdir -p /home/hdfs/namenode |
1 | <configuration> |
- 配置slaves 3.0是workers
1 | x.x.x.x worker1 |
- 格式化namenode
1 | $ hadoop namanode -format |
Spark安装部署
官网下载: https://spark.apache.org/downloads.html
1 | sudo tar zxvf spark-2.4.0-bin-hadoop2.6.tgz -C /usr/local |
添加环境变量
1 | spark |
- 打开/etc/hosts
1 | x.x.x.x Master |
- 配置
1 | $ cd /usr/local/spark24 |
1 | xyxj@u18_data1:~$ cd /usr/local/spark24 |
在末尾添加:
1 | mine settings |
在slaves后加入
1 | # |
启动
1 | hadoop namenode -format |
分别启动
sudo start-dfs.sh
sudo start-yarn.sh
使用pssh
安装
1 | sudo apt-get install pssh |
设置
1 | echo "alias pssh=parallel-ssh" >> ~/.bashrc && . ~/.bashrc |
拷贝公钥
1 | xyxj@Master:~$ ps aux | grep ssh |
这是在worker1客机就生成了 authorized_keys
允许root ssh登录
1 | sudo vim /etc/ssh/sshd_config #将PermitRootLogin yes |
向集群拷贝环境
1 | root@Master:~# pscp -h hosts.txt -r /usr/lib/jvm /usr/lib/ |
有个问题: 在启动的时候hadoop和spark都是带上版本号的,所以上面要重新传一下或者改成hadoop-2.6.0等
然后进行链接:
1 | root@Master:~# pscp -h hosts.txt -r /usr/local/hadoop-2.6.0 /usr/local/ |
启动
1 | /usr/local/hadoop/bin/hadoop namenode -format |
hadoop启动成功
1 | root@Master:~# /usr/local/hadoop/sbin/start-dfs.sh |
spark
1 | root@Master:~# /usr/local/spark24/sbin/start-all.sh |
在master上执行jps
1 | root@Master:~# jps |
问题
workder1: Warning: Permanently added ‘workder1’ (ECDSA) to the list of known hosts.
1 | vim /etc/ssh/ssh_config |

